0x00 前言
作者: R3dF09@腾讯玄武实验室
2015 年 3 月Google Project Zero发表文章Exploiting the DRAM rowhammer bug to gain kernel privileges。由于文中提到的缺陷比较难以修复,需要更新 BIOS 来提 高内存刷新的速度,引起了人们的担忧。然而由于 RowHammer 的运行需要在目 标主机上运行特定的汇编代码,实施攻击存在很大的难度。
本文旨在研究能否通过Javascript等脚本语言的动态执行触发RowHammer, 如果能够成功将极大增加RowHammer的攻击性。为了验证该思路,本文分析了Java Hotspot、Chrome V8、.NET CoreCLR 以及 Firefox SpiderMonkey的实现机制并 给出了可行性分析。
遗憾的是我们在这几个程序中,没有找到最优的利用方式。要么不存在相关 的指令,要么指令无法达到RowHammer要求,要么需要有额外的操作更改执行 环境才能触发,缺乏实际的攻击意义。
0x01 RowHammer
本节将简要回顾 RowHammer 存在的原理,其触发的机制,已经在利用时将 面临到的一些挑战。
1.1 What`s RowHammer?
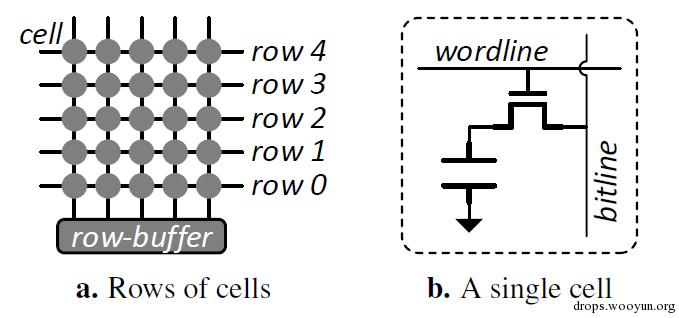
RowHammer是DDR3内存中存在的问题,通过频繁的访问内存中的一行(row) 数据,会导致临近行(row)的数据发生位反转。如图 1.1(a)所示,内存是由一系列 内存单元构成的二维数组。如图 1.1(b)所示每一个内存单元由一个晶体管和一个 电容组成,晶体管与wordline相连,电容负责存储数据。DRAM 的每一行(row) 有自己的wordline,wordline需要置高电压,特定行(row)的数据才能够访问。当 某一行的wordline置高电压时,该行的数据就会进入row-buffer。当wordline频 繁的充放电时,就可能会导致附近 row 的存储单元中的电容放电,如果在其被刷 新之前,损失过多的电压就会导致内存中的数据发生变化。
图 1.2 所示是一块内存,其中一个 row 为64kb(8KB)大小, 32k 个 row 组成一 个 Bank, 8 个 Bank 组成一个 Rank, 该 Rank 为 2G。此处需要注意不同的Bank有 专用的row-buffer,访问不同 Bank 中的 row 不会导致 wordline 的充放电。
内存中的电压是不能长期保存的,需要不停的对其进行刷新,刷新的速度为 64ms,所以必须在 64ms 内完成RowHammer操作。

1.2 RowHammer 触发的方法
表 1.1 所示为Google Project Zero所给出的可以触发RowHammer的代码段。
表 1.1
code1a:
mov (X), %eax // Read from address X
mov (Y), %ebx // Read from address Y
clflush (X) // Flush cache for address X
clflush (Y) // Flush cache for address Y
jmp code1a
其中 x, y 地址的选择非常重要,x, y 必须要在同一个 Bank,不同的 row 中。
因为不同的 Bank 有专用的row-buffer。如果 x, y 在同一个 row 中就不会对 wordline 进行频繁的充放电,也就不会触发RowHammer。
上述代码只是一种有效的测试方法,但并不是惟一的,归根到底我们所需要 的就是在 64ms 内让一个 wordline 频繁的充放电。
1.3 触发 RowHammer 指令
为了频繁的使 wordline 充放电,必须考虑 CPU 的 Cache, 如果当前地址在Cache 里面就不会访问内存,也就不会导致 wordline 的充放电情况。
表 1.2
| 指令 | 作用 |
|---|---|
| CLFLUSH | 将数据从 Cache 中擦除 |
| PREFETCH | 从内存中读取数据并存放在 Cache 中 |
| MOVNT* | 不经过 Cache 直接操作数据 |
表 1.2 中的指令都可以用来频繁的访问一个内存地址,并使相应的 wordline 充放电,如果要触发RowHammer, 需要上述指令的配合才能完成。
(注: 这些指令并不是惟一的触发方法,比如通过分析物理地址和L3 Cache的映射关系算法(不同的 CPU 架构实现可能不同),找到映射到同一个Cache set的一系列地址,通过重复访问这一系列的地址即可触发RowHammer。)
0x02 脚本层面触发 RowHammer
Google Project Zero给出的 POC 是直接以汇编的方式来运行,可以用来验证 内存是否存在安全问题。当前脚本语言大都存在 JIT 引擎,如果能够通过脚本控 制 JIT 引擎直接触发RowHammer,将会具有更大的攻击意义。为了分析其可行性,本节研究了Java Hotspot、Chrome V8等执行引擎的运行机制。
2.1 Java Hotspot
Hotspot是Oracle JDK官方的默认虚拟机,主要用来解释执行 Java 字节码,其 源码位于 Openjdk 下hotspot目录,可以独立编译。Java 字节码是堆栈式指令集, 指令数量少,共有 256 条指令,完成了数据传送、类型转换、程序控制、对象操 作、运算和函数调用等功能。Java 字节码存储在 class 文件中,作为 Hotspot 虚 拟机的输入,其在一定程序上是用户可控的。那么能否通过构造 class 文件,使 得 Hotspot 在执行时完成RowHammer呢?
Java Hotspot默认对字节码进行解释执行,当某方法被频繁调用,并且达到一定的阈值,即会调用内置的 JIT 编译器对其进行编译,在下次执行时直接调用编 译生成的代码。
Java 字节码解释器有两个实现,分别为模版解释器和 C++解释器,Hotspot 默 认使用模版解释器。Java 的 JIT 编译器有三个实现,分别为客户端编译器(C1 编 译器)、服务器端编译器(C2 编译器)以及 Shark 编译器(基于 LLVM)的编译 器。
图 2.1 所示为 Java 在不同平台下使用的虚拟机。


2.1.1 模版解释器触发 RowHammer?
a) 模版解释器工作原理
模版解释器是一种比较靠近底层的解释器实现,每一个字节码对应一个模版, 所有的模版组合在一起构成一个模板表。每一个模版实质上都是一段汇编代码, 在虚拟机创建阶段进行初始化。在执行 class 文件的时候,遍历字节码,每检测 到一个字节码就调用相应的汇编代码块进行执行,从而完成对于字节码的解释执 行。
为了完成对于字节码的解释执行,Hotspot 在初始化时还会生成多种汇编代 码块,用来辅助字节码的解释,比如函数入口代码块,异常处理代码块等。查看 Hotspot 中生成的代码块和模版可以采用命令java –XX:+PrintInterpreter指令来 完成。
针对各个字节码的模版中汇编代码比较庞大,比如字节码invokevirtual对应 的代码块共有352 bytes,字节码putstatic有512 bytes。
b) 解释器能否触发 RowHammer?
字节码在解释执行的时候会产生汇编代码,那么是否可以通过 class 文件让解释器生成 RowHammer 需要的指令呢?
通过分析,字节码对应的模版和辅助代码块的指令中没有prefetch,clflush以 及movnt*系列指令,所以直接通过构造字节码,然后使用模版解释器来触发 RowHammer 是不可行的。
***||2.1.2 JIT 编译器触发 RowHammer?
a) C1 编译器工作原理  JIT 编译器也是一种编译器,只不过其是在程序动态运行过程中在需要的时候 对代码进行编译。其编译流程与一般编译器基本相同。
C1 编译器是客户端使用的 JIT 编译器实现,其主要追求编译的速度,对于代 码的优化等要相对保守。
Hotspot编译器默认是异步编译,有线程CompilerThread负责对特定的方法 进行调用,当方法调用次数达到一定阈值时将会调用 JIT 编译器对方法进行编译, 该阈值默认为 10000 次,可以通过–XX:+CompileThreshold参数来设置阈值。
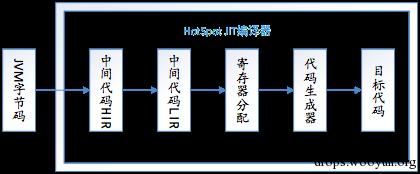
图 2.2 从代码级别看,C1 编译器共包含如下几个步骤
表 2.1
typedef enum {
_t_compile,
_t_setup,
_t_optimizeIR,
_t_buildIR,
_t_emit_lir,
_t_linearScan,
_t_lirGeneration,
_t_lir_schedule,
_t_codeemit,
_t_codeinstall,
max_phase_timers
} TimerName;
C1 编译器执行流程大致如图 2.2 所示:
1) 生成 HIR (build_hir)
C1 编译器首先分析 JVM 字节码流,并将其转换成控制流图的形式,控制流 图的基本块使用 SSA 的形式来表示。HIR 是一个层级比较高的中间语言表示 形式,离机器相关的代码还有一定的距离。
2) 生成 LIR (emit_lir)
遍历控制流图的各个基本块,以及基本块中个各个语句,生成相应的 LIR 形 式,LIR 是一个比较接近机器语言的表现形式,但是还不是机器可以理解的 代码。
3) 寄存器分配
LIR 中使用的是虚拟寄存器,在该阶段必须为其分配真实可用的寄存器。C1为了保证编译的速度采用了基于线性扫描的寄存器分配算法
4) 生成目标代码
真正生成平台相关的机器代码的过程,在该阶段遍历 LIR 中的所有指令,并 生成指令相关的汇编代码。主要是使用了 LIR_Assembler 类。
表 2.2
LIR_Assembler lir_asm(this);
lir_asm.emit_code(hir()->code());
通过遍历LIR_List依次调用,依次调用各个指令相关的emit_code(如表 2-3), LIR 中的指令都是继承自LIR_Op
表 2.3
op->emit_code(this);
以 LIR_Op1 为例,其emit_code方法为
表 2.4
void LIR_Op1::emit_code(LIR_Assembler* masm) { //emit_code
masm->emit_op1(this);
}
假设 LIR_Op1 的操作码为LIR_prefetchr
表 2.5
case lir_prefetchr:
prefetchr(op->in_opr());
break;
最终会调用prefetchr函数,该函数为平台相关的,不同的平台下实现不同, 以 x86 平台为例,其实现位于assembler_x86.cpp
表 2.6
void Assembler::prefetchr(Address src) {
assert(VM_Version::supports_3dnow_prefetch(), "must support");
InstructionMark im(this);
prefetch_prefix(src);
emit_byte(0x0D);
emit_operand(rax, src); // 0, src
}
最终将会生成相应的机器码。
b) 能否触发 RowHammer
C1 编译器是否能够触发RowHammer? 经过分析发现,在 x86 平台下封装了prefetch相关的指令,确实是有希望控制产生prefetch指令。
从底层向上分析,如果要生成 prefetch 指令,在 LIR 层需要出现 LIR_op1 操 作,且操作码需要为lir_prefetchr或者 lir_prefetchw,进一步向上层分析,要在 LIR 层出现这样的指令,在从字节码到 HIR 的过程中必须能够调用到GraphBuilder::append_unsafe_prefetch函 数 。 该 方 法 在GraphBuilder::try_inline_instrinsics函 数 中 调 用 , 进 一 步 分 析 只 需 调 用sun.misc.unsafe的 prefetch 操作即可触发。通过深入分析,Hotspot 确实是支持 prefetch 操作,然而在 Java 的运行库rt.jar中,sun.misc.unsafe并没有声明 prefetch 操作,导致无法直接调用,需要更改rt.jar才能触发成功。这样就失去了攻击的 意义。
在 Hotspot 中还存在clflush这种指令,在hotspot的初始化阶段,其会生成 一个代码块。如下所示:
表 2.7
__ bind(flush_line);
__ clflush(Address(addr, 0)); //addr: address to flush
__ addptr(addr, ICache::line_size);
__ decrementl(lines); //lines: range to flush
__ jcc(Assembler::notZero, flush_line);
该部分代码在 C1 编译器编译完成之后有调用
表 2.8
// done
masm()->flush(); //invoke ICache flush
对当前代码存储的区域进行 cache flush
表 2.9
void AbstractAssembler::flush() {
sync();
ICache::invalidate_range(addr_at(0), offset());
}
这种方法可以对内存做 cache flush, 主要问题在于代码存储的区域在堆中是 随机分配的,无法直接指定 cache flush 的区域,而且由于涉及到编译的操作,无 法在短时间内大量产生 clflush 指令。
c) 其它编译器实现
C2 编译器与 C1 编译器有一定的相似性又有很大的不同,由于主要在服务器 端使用所以 C2 编译器更加注重编译后代码的执行效率,所有在编译过程中相对 C1 编译器做了大量的优化操作,但是在生成汇编代码的时候两者使用的是同一 个抽象汇编,所以 C2 编译器与 C1 编译器应该大体相同,能够生成 prefetch 指令, 但是在默认的情形下无法直接使用。
Shark 编译器是基于 LLVM 实现的,一般都不会开启,没有对该编译器进行进 一步的分析。
2.2 Chrome V8
V8 是 Google 开源的 Javascript 引擎,采用 C++编写,可独立运行。V8 会直接 将 JavaScript 代码编译成本地机器码,没有中间代码,没有解释器。其执行机制 是将 Javascript 代码转换成抽象语法树,然后直接 walk 抽象语法树,生成相应的 机器码。
在 V8 生成机器码的过程中无法生成 prefetch, clflush, movnt*系列指令。但是 在 V8 执行的过程中可能会引入 prefetch 指令。
产生 prefetch 的函数为
表 2.10
MemMoveFunction CreateMemMoveFunction() {
表 2.11
__ prefetch(Operand(src, 0), 1);
__ cmp(count, kSmallCopySize);
__ j(below_equal, &small_size);
__ cmp(count, kMediumCopySize);
__ j(below_equal, &medium_size);
__ cmp(dst, src);
__ j(above, &backward);
该函数的主要作用是当缓冲区无法满足指令的存储时,需要将缓冲区扩大一 倍,在该过程中会调用一次 prefetch 指令,但是调用的此处远远不足RowHammer触发的条件。
2.3 .NET CoreCLIR
CoreCLR 是.NET 的执行引擎,RyuJIT 是.NET 的 JIT 实现,目前已经开源。作为 Java 的竞争对手,.NET 大量参考了 Java 的实现机制,从字节码的设计,到编译 器的实现等,都与 Java 有几分相似。在 RyuJIT 的指令集定义中只定义了一些常 见的指令(图 2.3),但是没有 RowHammer 需要的指令,所以无法直接触发。但是 在 CoreCLR 的 gc 中存在 prefetch 操作(表 2.12),然而该指令默认是被置为无效的 (表 2.13)。

图 2.3
表 2.12
void gc_heap::relocate_survivor_helper (BYTE* plug, BYTE* plug_end) {
BYTE* x = plug;
while (x < plug_end) {
size_t s = size (x);
BYTE* next_obj = x + Align (s);
Prefetch (next_obj);
relocate_obj_helper (x, s);
assert (s > 0);
x = next_obj;
} }
表 2.13
//#define PREFETCH
#ifdef PREFETCH
__declspec(naked) void __fastcall Prefetch(void* addr) {
__asm {
PREFETCHT0 [ECX]
ret
};
}
#else //PREFETCH
inline void Prefetch (void* addr) {
UNREFERENCED_PARAMETER(addr);
}
#endif //PREFETCH
2.4 Firfox SpiderMonkey
SpiderMonkey是 Firfox 默认使用的带有 JIT 的 Javascript 引擎,在SpiderMonkey中没有RowHammer所需要的指令出现。
0x03 总结
本文研究的主要目的是希望通过 JIT 引擎来触发 RowHammer 的执行,为了 提高脚本语言的执行效率,当前绝大多数脚本引擎都带有 JIT 编译器以提高运行 的效率。本文研究了Hotspot、V8、RyuJIT和SpiderMonkey,其中并没有找到比 较好的触发 RowHammer 的方法,当然依旧有一些 JIT 还没被研究,不过通过以 上研究证明 JIT 触发的方式非常困难,原因主要有以下几点:
1) RowHammer 的触发条件比较苛刻,64ms 内触发成功也就意味着无关指令的 数目必须很少,否者在 64ms 内 wordline 无法充放电足够的次数。
2) Cache 相关的指令并不常用,RowHammer 运行需要使用 CLFLUSH, PREFETCH, MOVNT*系列指令,这些指令在实际的使用过程中并不常见,在用户态进行 Cache 相关操作的情形比较少见。
3) 站在 JIT 开发人员的角度考虑,为了实现跨平台,一般会对指令进行抽象, 然后在各个平台上具体实现。抽象的指令一般都尽可能少,因为每抽象一个 指令就需要再添加大量的代码。在分析的 JIT 引擎中只有 hotspot 抽象了 prefetch 指令,引擎都尽可能少的去抽象编译器要用到的指令,想通过脚本 直接生成需要的汇编指令很困难。(特例是如果采用了第三方引擎(比如 AsmJit),引擎会抽象所有的汇编指令,则有更大的可能性触发,然而当前主 流语言的 JIT 部分大都是独立开发,而第三方引擎则多是从这些代码中提取 并逐步完善的)。
4)在整个分析过程中发现指令出现的原因主要是辅助 JIT 编译,比如使用 prefetch 提高某些数据存取的速度,使用 CLFLUSH 刷新指令缓冲区等。指令 出现的次数与频率,远远达不到 RowHammer 的要求。
参考资料
-
Google Project Zero 博客 http://googleprojectzero.blogspot.com/2015/03/exploiting-dram-rowhammer-bug-to-gain.html
-
Paper: Flipping Bits in Memory Without Accessing Them: An Experimental Study of DRAM Disturbance Errors http://users.ece.cmu.edu/~yoonguk/papers/kim-isca14.pdf
-
高级语言虚拟机群组 http://hllvm.group.iteye.com/ 
-
各语言开放的源代码